
谷歌AI播客剛火,Meta就開源了平替,效果一言難盡
2024-10-29 01:34:55 2
隨著谷歌和 Meta 相繼推出基於大語言模型的 AI 播客功能,將極大地豐富人類使用者與 AI 智慧體互動的體驗。
上個月,谷歌宣佈對旗下 AI 筆記應用 NotebookLM 進行一系列更新,允許使用者生成 YouTube 影片和音訊檔案的摘要,甚至可以建立可共享的 AI 生成音訊討論。加上此前支援的谷歌文件、PDF、文字檔案、谷歌幻燈片和網頁,NotebookLM 的用例和覆蓋範圍進一步擴大。
本月初,AI 大牛 Karpathy 發推表示自己只用了兩個小時就建立了一個 10 集的系列部落格 —— 歷史謎團(Histories of Mysteries),其中就使用 NotebookLM 將每個主題的維基百科條目連結在一起,並生成播客影片;同時也使用 NotebookLM 編寫部落格 / 劇集描述。

就這兩天,Meta 推出了 NotebookLM 的開源平替版 ——NotebookLlama,它使用 Llama 模型進行大部分任務處理,包括 Llama-3.2-1B-Instruct、Llama-3.1-70B-Instruct 和 Llama-3.1-8B-Instruct。
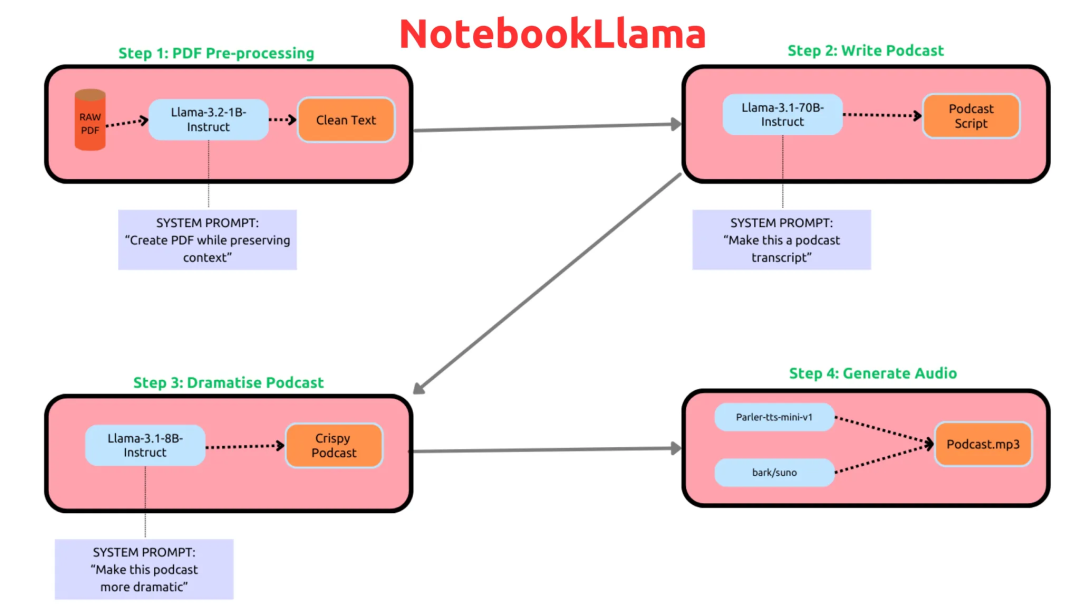
下圖為 NotebookLlama 執行流程,首先從檔案(比如新聞文章或部落格文章)建立轉錄文字,然後新增「更多戲劇化」和中斷,最後將轉錄文字饋入到開放的文字到語音模型。
據外媒 Techcrunch 報道,NotebookLlama 的效果聽起來不如谷歌 NotebookLM 好,帶有明顯的機器人口音,並且往往會在奇怪的時刻「互相交談」。不過,專案背後的 Meta 研究人員表示,使用更強大的模型還可以提高質量。
Meta 研究人員在 NotebookLlama 的 GitHub 頁面寫到,「文字到語音模型限制了聲音的自然程度。」此外,編寫播客的另一種方法是讓兩個智慧體就感興趣的主題進行討論並編寫播客大綱。現在,Meta 只使用了一個模型來編寫播客大綱。
就像下面所展示的,雖然播客內容還有一些粗糙,但它聽起來已經很不錯了。
<video data-src="https://mp.weixin.qq.com/mp/readtemplate?t=pages/video_player_tmpl&action=mpvideo&auto=0&vid=wxv_3699165864755544073" src="https://mp.weixin.qq.com/mp/readtemplate?t=pages/video_player_tmpl&action=mpvideo&auto=0&vid=wxv_3699165864755544073"></video>
對於 Meta 的 NotebookLlama,有人直言聽起來糟糕透了,要想真正地對標谷歌的 NotebookLM,就要在語音轉換效果上接近人類水平。不過也有人認為,雖然目前效果不佳,但隨著所有程式碼的開源,使用者可以自定義嘗試不同的提示方法等,相信未來會變得更好。
雖然效果還是差點意思,但也有網友表示:「現在是時候讓 Google 加快步伐了,Meta 已經緊隨其後趕上來了,開源 NotebookLM。」

專案介紹
根據 Meta 釋出的教程配方,你可以基於 PDF 檔案構建播客。
專案地址:https://github.com/meta-llama/llama-recipes/tree/main/recipes/quickstart/NotebookLlama
第一步:對 PDF 進行預處理。即使用 Llama-3.2-1B-Instruct 對 PDF 進行預處理,並將其儲存為.txt 檔案;
第二步:轉錄文字編寫器。使用 Llama-3.1-70B-Instruct 模型從文字中編寫播客轉錄文字;
第三步:對內容重新最佳化,新增戲劇性。使用 Llama-3.1-8B-Instruct 模型使轉錄文字更具有創意;
第四步:文字到語音。使用 parer -tts/parer -tts-mini-v1(文字到語音模型)和 bark/suno 生成會話播客。
不過,還有幾個值得大家注意的點:
首先,在步驟 1 中,需要提示 1B 模型不要修改文字或對文字進行總結,並嚴格清理掉可能在 PDF 轉錄過程中出現的多餘字元或垃圾字元。
其次,對於步驟 2,你也可以使用 Llama-3.1-8B-Instruct 模型,然後對比不同模型的效果。專案中採用的是 70B 模型,原因在於它為測試示例提供了更具創意的播客記錄。
對於步驟 4,你也可以使用其他模型進行擴充套件,較新的模型可能聽起來更好。
想要順暢的執行該專案,你需要有 GPU 伺服器或者使用 70B、8B 和 1B Llama 模型的 API 提供商。如果你採用的是 70B 模型,那麼需要一個總記憶體約為 140GB 的 GPU 來以 bfloat-16 精度進行推理。
退一步講,如果你的 GPU 並不是很好,也可以使用 8B 模型跑通整個 pipeline。
接下來是安裝。在開始之前,請確保使用 huggingface cli 登入,然後啟動 jupyter notebook ,以確保能夠下載 Llama 模型。
接著執行程式碼:
git clone https://github.com/meta-llama/llama-recipescd llama-recipes/recipes/quickstart/NotebookLlama/pip install -r requirements.txt
Notebook 1:Notebook 1 用於處理 PDF,並使用新的 Feather light 模型將其處理為.txt 檔案。
Notebook 2:Notebook 2 將接收 Notebook 1 處理後的輸出,並使用 Llama-3.1-70B-Instruct 模型創造性地將其轉換為播客指令碼。如果你擁有豐富的 GPU 資源,也可以使用 405B 模型進行測試!
Notebook 3:Notebook 3 採用了之前的文字,並提示 Llama-3.1-8B-Instruct 在對話中新增更多的戲劇化和中斷。
Notebook 4:最後,Notebook 4 從上一個 notebook 中獲取結果並將其轉換為播客。專案中使用了 parer -tts/parer - ttts -mini-v1 和 bark/suno 模型進行對話。
這裡有一個問題:Parler 需要 4.43.3 或更早版本的 transformer,但對於 pipeline 中的步驟 1 到 3,需要最新的版本,所以需要在最後一個 notebook 中切換版本。
最後,專案列出了未來需要改進的地方:
語音模型:TTS 模型使語音聽起來不是很自然,未來可以納入更好的模型;
更好的提示;
支援提取網站、音訊檔案、YouTube 連結等。
參考連結:https://techcrunch.com/2024/10/27/meta-releases-an-open-version-of-googles-podcast-generator/?guccounter=1
本站內容由互聯網用戶自發貢獻,該文觀點僅代表作者本人。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。如發現本站有涉嫌抄襲侵權/違法違規的內容,請發送郵件至舉報,壹經查實,本站將立刻刪除。