
中國智算建設潮背後,誰在推動十萬卡叢集
2024-11-14 01:33:01 1

文|趙豔秋
編|牛慧
在打造十萬卡叢集上,幾家國內頭部企業已有動作。
在11月12日舉辦的百度世界2024大會上,百度集團執行副總裁、百度智慧雲事業群總裁沈抖透露,為了支撐大模型進一步的高速發展,百度在打磨十萬卡叢集能力方面,已在兩大問題上取得關鍵突破。與此同時,位元組和阿里在智算上投入巨大,今年以來,華為也聯合廠商在攻克更大規模叢集。
是否有必要打造十萬卡叢集?過去24個月,由於大模型超級應用還未出現,中國業界出現了反思——大模型全球性的狂熱,究竟是一場新的技術革命,還是新一輪泡沫?
在這次大會上,百度創始人李彥宏披露了一個數字,文心大模型日均呼叫量達到15億,而6個月前是2億。“‘應用來了’,代表了我們對大模型和生成式AI當下的認知和判斷。” 李彥宏稱。這個在下半年突然變得陡峭的曲線,在一定程度上給出了佐證。
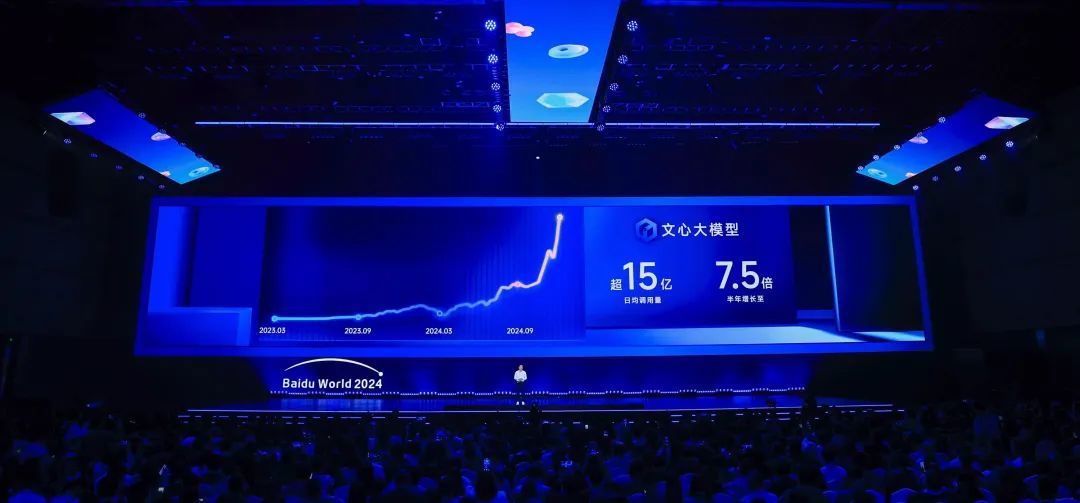
這也是當下中國雲廠商開展技術準備的現實考量。由於投入和晶片上的限制,中國雲廠商的表現並不激進。但他們在客戶快速增長的需求下,也在分步走向十萬卡叢集。
01
企業智算投資的熱情高了
百度傑出系統架構師王雁鵬,最近幾個月頻繁接觸到高校客戶,“他們對算力的需求在增多”。
今年諾貝爾物理學獎、化學獎都頒給了人工智慧相關專家,引發了廣泛關注。“大家最興奮的是,原來AI for Science要由各種不同的模型去做,但現在搞蛋白質的、搞數學的......都可以‘揉’到大模型的方式中來,核心架構甚至全都是transformer。”王雁鵬告訴數智前線。高校的熱情普遍提高了,最近預算變多,都拿到資金建設智算基礎設施。
像上海交通大學,已轉變傳統科研模式,期望科學與AI更緊密的結合。他們與百度智慧雲合作建成了自己的AI for Science科學資料開源開放平臺,支撐白玉蘭科學大模型的訓練。依託AI for Science平臺,上海交大已在Nature Computational Science封面,發表了AI+城市的科學成果。在公開招投標平臺上,近期更多高校釋出智算相關招標公告。
車企是當下智算的採購大戶。“我們調研,使用者已願意為好用的智駕買單。”一位大型車企人士說。而且,端到端智駕技術,比原來由很多小模型串聯起來的智駕“更擬人化”,成為行業的主流方案。明確的方向,讓車企投入意願更強烈。該人士判斷,未來1~2年內,車企智算算力會再翻兩番左右。

“在教育行業,最大的夢想就是實現大規模因材施教。”好未來集團CTO田密說,“AI老師讓我們看到了一絲曙光。有了大模型,所有的AI教育科技都值得重做一遍。” 大模型可以解題、講題、口語練習、批改作業,為學生做個性化學習推薦。
“大廠可以從零開始做,小廠透過API呼叫或微調、RAG就可以。作為中廠或垂直領域的龍頭企業,我們還是要基於最優秀的開源模型,做好後訓練。”田密說。去年,好未來推出九章大模型MathGPT。為此,好未來在百度智慧雲上,自有和租賃數千卡,這在教育行業中是最好最高的。大模型在以各種形式落地,如學習機、App,也透過API向社會開放,手機、平板、PC和新能源車都開始了呼叫。

在餐飲行業,消費者已不知不覺用上了大模型技術。“百勝中國是最早開始使用生成式AI的餐飲企業。”百勝中國CTO張雷說。它是國內規模最大的餐飲公司。在人們經常使用的App小程式、外賣平臺各渠道中,百勝採用了百度智慧雲的客悅AI智慧客服系統,解決肯德基、必勝客線上點餐中非常多樣化的服務需求,每天已協助處理超15萬次消費者溝通。
張雷稱,未來將以AI原生方式,在管理、運營、生產和交易的各個方面進行技術重構。
從去年開始,國家電網基於文心大模型和千帆平臺,結合電力行業高質量資料,在共創電力行業大模型基礎底座,在排程、裝置、營銷等六大專業領域探索AI原生應用。近期國網就會正式對外發布相關成果。

“我理解,所有行業都已被transformer給重構了。”好未來田密說。越來越多的大中型網際網路企業、車企、頭部央企等,都在訓練自己的行業或企業大模型。
他們的共同特點是,有大量私域資料和獨有業務,有研發力量,但不會從頭去訓練通用大模型,而是在開源或商用模型上做深入的後訓練,適配各類場景,搭建自己的資料飛輪,並有商業預期。這些企業的需求,也進一步拉動了智算市場。
值得關注的是,在大模型正規化下,算力與演算法的重要性開始對等了,這讓企業的投入佔比發生了變化。
“我們算了一筆賬。四五年前開始研發智駕時,要投入相當多的演算法和規則開發工程師,人力、資料和算力的投入比是6:2:2。”一位車企人士說,“但現在端到端智駕研發,需要更大的算力。我們初步預測,上述比例將變為2:3:5,50%甚至更高的投入是算力。”
有趣的是,這些龍頭企業無論採用公有云,還是自建資料中心,都不約而同找到了雲廠商。“我們主動找到了百度智慧雲。”好未來田密說,“你會發現,在Infra(基礎設施)的投入上,只有大廠才能做得這麼細緻。”

而IDC中國研究總監劉麗輝介紹,到2026年,半數以上的企業,都會與雲廠商達成生成式AI基礎設施、相關平臺工具等方面的合作。
02
壓力給到了雲廠商
百度王雁鵬觀察,在投入踴躍的企業中,行業龍頭典型的算力需求在1000卡~5000卡規模,而大模型創企的需求則在萬卡水平。
這些企業在訓練和推理過程中,遇到了各種問題,他們對智算基礎設施提出了四個主要的訴求——高速網路互聯、叢集穩定性、資源利用率、大模型訓練和推理工具等。而這些需求與CPU雲時代截然不同。
比如有人把GPU比作賽車,要讓賽車效能發揮到極致,就要給它建立專業賽道。在搭建GPU叢集時,企業要求雲廠商提供一個更好的網路硬體互聯架構。
穩定性是一件要命的事。CPU的功耗只有兩三百瓦,GPU已經1500瓦了。黃仁勳因此被戲稱為“核彈狂魔”。功耗高代表著整合度高,這就容易出故障。“我們算過,一個千卡叢集,按照現有市場價格,一天的租金是二三十萬元。平臺穩定性不好了,我們的損失就很大。”一家車企人士說。而影片大模型企業生數科技人士告訴數智前線,他們核心的訴求是“穩定性”。平臺穩定,確保他們在影片生成的核心技術“高一致性”上實現突破。
資源利用率也是企業最關注的問題,因為GPU太貴了,利用率左右著ROI。
而這些訴求,把壓力給到了雲廠商。“過去一年多,大模型正在重構AI計算模式。”一位雲廠商的資深人士說,“我從來沒有看到過任何一個技術浪潮,能夠像這一輪大模型,從上到下對我們的技術有如此大的顛覆。”
此前,基礎設施是以CPU為核心的體系。它的核心點是極致彈性、極致價效比,大家最大的驅動力是提效降本。

到了大模型時代,基礎設施轉向了極致高密、極致互聯與極致規模。國外今年已從十萬卡向百萬卡叢集邁進。用不了太長時間,可能一個資料中心,就會“縮到”一個機櫃裡或一個節點上。
基礎設施從過去的提效降本,轉變成一個全面追求技術創新,來驅動整個業務大發展的階段。每一個從業者也都在朝著如何能夠去追趕上scaling law的發展去奔跑。在一次會議中,百度集團副總裁侯震宇介紹,最近幾年,在百度內部提及最多的是800G/T級互聯、高密儲存、異地異網異構排程、訓推一體.....
由於過去十多年在整體AI上的投入,百度從2009年開始,在中國網際網路企業中第一家開始使用GPU做叢集加速,2021年已建成三四千卡單一任務的GPU叢集,並逐步形成了有豐富技術棧的百度百舸異構計算平臺。
“CPU的IaaS是一個通用平臺,但GPU的IaaS不一樣,更追求GPU算力端到端的效能最優,要給它提供更厚的技術棧,算力才容易發揮出來。”百度王雁鵬對數智前線解釋。
基於百度百舸的技術棧,解決了龍頭企業在算力上的問題。在長安汽車,最初GPU綜合利用率不太高。長安汽車和百度智慧雲,應用百舸平臺,做好訓練任務的編排和排程,GPU利用率提升了40%以上。
影片大模型創企生數科技稱,基於百度百舸穩定的超大算力叢集,在OpenAI推出Sora僅40天后,推出了自研影片大模型Vidu。在訓練中,他們應用了百舸平臺的算力叢集的任務分發、佇列排程和訓練加速,“縮短了 Vidu的研發週期”。
“我們迭代的速度是非常快的,無論是新功能,還是模型基礎能力上。”在Vidu上線逾百日之際,生數科技在11月13日推出Vidu 1.5新版本,率先攻克“多主體一致性”難題。
由於最早在市場上推出模型,生數科技已在影視、動畫、文旅有落地。比如,近期漫威電影《毒液3》的中國水墨風格AI宣傳片,就是Vidu生成的。
03
奔向十萬卡
國內雲端計算廠商還在更進一步,但他們的做法和考量也更理性和現實。
在海外,美國市場在經歷了一個充分有效的競爭後,之前很熱鬧的大模型公司都在賣身,今年做基礎大模型的企業已迅速收縮到五家——OpenAI、Anthropic、Meta、谷歌,以及馬斯克旗下的xAI。
而這些巨頭的算力競爭門檻已達到十萬卡規模。微軟計劃到明年底,向 OpenAI 提供約30萬個英偉達最新GB200圖形處理器。但OpenAI似乎並不滿意,也與甲骨文達成了協議,甲骨文正在設計一個超級資料中心,將達到一千兆瓦電力,轉換過來就是50多萬卡英偉達GPU;
Meta的小扎也不甘落後,稱Llama 4模型正在一個10萬片H100 GPU叢集上訓練;馬斯克的xAI今年7月已建成十萬卡叢集,並將在未來幾個月內再增加10萬卡,其中5萬卡將是英偉達H200。
在百度世界2024大會上,沈抖披露,百度已解決了10萬卡叢集兩個難題。一個是在一雲多芯情況下,兩種晶片混合訓練效能折損,控制在5%以內,這是業界領先水平。這一技術是針對晶片供應緊張,以及部分企業對國產算力有強需求而研發。
另一個難題是跨地域機房部署,百舸將單一訓練任務叢集的效能折損控制在4%以內,這也是業界領先水平。它解決的是電力問題和機房空間問題。10萬卡叢集一天要吃掉300萬千瓦時電力,相當於北京東城區一天的居民用電量;所需的佔地,相當於14 個標準足球場。它透過高效拓撲結構、跨地域無擁塞高效能網路和高效模型並行訓練等方案,在橫跨幾十公里的多機房上實現。
不過,業界如今有一個疑問,OpenAI在2020年提出的Scaling Law是否還成立?是否有必要追趕十萬卡叢集?王雁鵬坦言,他們看到Scaling Law確實在放緩。這也是OpenAI o1比較火的一個原因,它採用強化學習(Self-play)模式,開創了模型scaling的新維度。
一些國內龍頭企業,其實在半年多前已將更多精力轉向強化學習。透過算力創造更多資料,由人們給每一步打分、做資料標註,透過獎勵模型去強化它,讓模型更智慧。

強化學習讓模型訓練對算力的需求也降低了不少。但這並不意味著國內就原地踏步在數千卡到萬卡叢集。大模型正進入更多產業,王雁鵬預估,明年算力需求還會以訓練為主,算力需求在高速增長,企業對算力在效能和成本上,也提出進一步的訴求。
“比如大模型創企,他們有很強的融資壓力,所以對成本的訴求非常強。”王雁鵬說。
當下,公有云是企業進行大模型訓練的主流方式。雲廠商常常採用“服務一個企業,搭建一個叢集的方式”。但這種方式存在明顯劣勢,即在企業訓練任務不處於高峰期時,叢集中的計算資源處於閒置狀態,造成資源浪費。而當10萬卡叢集出現後,雲廠商就可以依靠這個大型叢集,為眾多企業提供服務,根據不同企業的需求,動態分配計算資源,不僅提高了資源利用率,也降低了企業的成本。
“當我們能解決了十萬卡叢集技術,比如上述的跨地域RDMA技術、多芯混訓技術、容錯技術,就可以不需要建一個大的單一機房,而是把幾個機房融合在一起,提供一個更好的雲平臺,也給大家一個更好的成本。多芯技術也是一樣的邏輯。”他進一步說。
在與國內企業的相互合作和推動下,中國雲廠商正在加速平臺建設,推動大模型技術浪潮,在市場的快速演進。
©本文為數智前線(szqx1991)原創內容
本站內容由互聯網用戶自發貢獻,該文觀點僅代表作者本人。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。如發現本站有涉嫌抄襲侵權/違法違規的內容,請發送郵件至舉報,壹經查實,本站將立刻刪除。